Our guest post today is by Sarah Wilson, a Senior Lecturer in Sociology in the School of Applied Social Science at the University of Stirling. Sarah’s research interests are in the sociology of families, relationships and personal life, with a methodological focus on developing visual, audial and artistic qualitative research. In this post, Sarah reflects on her qualitative secondary analysis of data from the Timescapes ‘Siblings and Friends’ project, a longitudinal dataset with which we are also working, and how this process prompted reflection on her own research practices.
This post draws on Sarah’s 2014 article in Sociological Research Online, ‘Using secondary analysis to maintain a critically reflexive approach to qualitative research’ which you can read here: http://www.socresonline.org.uk/19/3/21.html
Using qualitative secondary analysis as a tool of critical reflexivity
 Maintaining a critical, reflexive approach to research when engaging in specialised work is not easy. Partly because of the need to convince funders of their expertise, researchers often focus on relatively circumscribed areas of inquiry, with samples drawn from particular social groups.
Maintaining a critical, reflexive approach to research when engaging in specialised work is not easy. Partly because of the need to convince funders of their expertise, researchers often focus on relatively circumscribed areas of inquiry, with samples drawn from particular social groups.
My own research has focused on samples characterised as ‘vulnerable’; notably young people affected by parental substance misuse or living ‘in care’. Often this work has been located within more ‘applied’ approaches to social research, and influenced by funders’ concerns. Such work is valuable. However, the segregation often maintained between research with young people from more ‘vulnerable’ and more ‘ordinary’ backgrounds may reinforce perceptions that the experiences, values and aspirations of members of each ‘category’ are distinct. As Law (2009) argues, research is ‘performative’, helping to re-produce and reinforce perceptions of social groups. In the current political context, such distinctions may even implicitly reinforce the stigmatisation of ‘troubled families’. As such, there is a need to find ways to subject one’s own research practice to scrutiny.
To better situate my previous research, I engaged in qualitative secondary analysis of the longitudinal Timescapes ‘Siblings and Friends’ (SAF) study to prepare for a new project with ‘looked after’ young people: Young people creating belonging: spaces, sounds and sights (ESRC RES-061-25-0501). The idea was to reflect on my own approaches, and previous framings of interview questions in the light of the very rich SAF project data which involved predominantly ‘ordinary’ young people from across the UK. This proved to be an illuminating, if demanding, process that prompted further thought about both projects.
Importantly, this analysis highlighted significant commonalities between the experience of those included in ‘ordinary’ and ‘vulnerable’ samples. Notably, the SAF data included several accounts of strained family relationships, of parental mental ill-health and of undesirable housing conditions that suggested family circumstances comparable to those in my previous work on parental substance misuse. However, the SAF interview questions situated violence outside of the home. As Gillies (2000) argues, even where ‘difficult’ accounts within ‘ordinary’ samples are identified, they are often not written up. As such, the complexity and pain within ‘ordinary’ families may be under-estimated in research, and potentially more easily obscured within political discourse. Similarly, the everyday ambiguity and minor conflicts associated with ‘ordinary’ siblings and parents sharing limited space may be downplayed. Such ambiguities and tensions led several SAF respondents to seek out friends’ homes, or private corners of their own, to escape from family life at least for a time. I had previously associated such strategies with young people affected by parental substance use, many of whom often spent time at friends’ houses. However, this analysis suggested a more nuanced understanding of the importance to the latter group of employing strategies that could be presented as ‘ordinary’ teenage practices. The process of secondary analysis also highlighted uncomfortable omissions from my previous research in which, for various reasons, greater emphasis was placed on the respondents’ own potential substance use, than on their school work and employment aspirations. The predominance of such concerns in the SAF accounts led me to worry that my own research had reflected and performed perceptions of education as less important to ‘vulnerable’ than to ‘ordinary’ young people.
In conclusion, qualitative secondary analysis is a ‘labour-intensive, time-consuming process’ that Gillies and Edwards (2005: para24) compare to primary data collection. However, it presents a useful tool to subject assumptions built up over a specialised research career to scrutiny.
References
Gillies, V. (2000) ‘Young people and family life: analysing and comparing disciplinary discourses’, Journal of Youth Studies, 3(2): 211-228
Gillies, V. and Edwards, R. (2005) ‘Secondary analysis in exploring family and social change: addressing the issue of context’, Forum: Qualitative Social Research, 6(1): art 44.
Law, J. (2009), ‘Assembling the World by Survey: Performativity and Politics’, Cultural Sociology, 3, 2, 239-256.
Wilson, S. (2014) ‘Using secondary analysis to maintain a critically reflexive approach to qualitative research’ Sociological Research Online, 19(3), 21 http://www.socresonline.org.uk/19/3/21.html

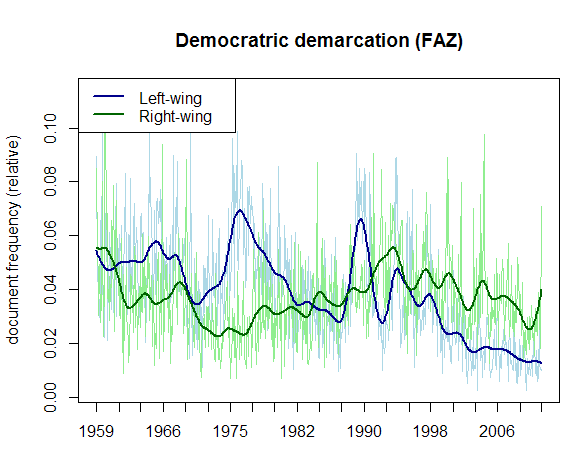 Distribution indicates that demarcation towards left-wing actors and ideology long-time superseded right-wing demarcation. Soon after 1990, the latter became the primary discourse subject of threats of German democracy. The enormous benefit of automatic classification is that it allows for easy comparison of publications (e.g. other newspapers) or relations with any other category. For instance, the distribution of “reassurance of democratic identity”, a third category I measured, strongly correlates with right-wing demarcation, but not with left-wing demarcation. Such a finding can be realised only by a combination of the qualitative and the quantitative paradigm.
Distribution indicates that demarcation towards left-wing actors and ideology long-time superseded right-wing demarcation. Soon after 1990, the latter became the primary discourse subject of threats of German democracy. The enormous benefit of automatic classification is that it allows for easy comparison of publications (e.g. other newspapers) or relations with any other category. For instance, the distribution of “reassurance of democratic identity”, a third category I measured, strongly correlates with right-wing demarcation, but not with left-wing demarcation. Such a finding can be realised only by a combination of the qualitative and the quantitative paradigm.
 Our guest post today is by Sue Bellass, a PhD student in the School of Nursing, Midwifery, Social Work and Social Sciences at the University of Salford. Her thesis, which she is due to submit in August, has been exploring how intergenerational families are affected by young onset dementia over time.
Our guest post today is by Sue Bellass, a PhD student in the School of Nursing, Midwifery, Social Work and Social Sciences at the University of Salford. Her thesis, which she is due to submit in August, has been exploring how intergenerational families are affected by young onset dementia over time.
 researchers and data producers, with specialisation in ethics of data use: consent, confidentiality, anonymization and secure access to data. She also teaches workshops on secondary analysis of qualitative data. Libby worked as a Senior Research Archivist at the University of Leeds, where she was responsible for creating and managing the Timescapes archives and providing support for those using the data. Libby has published individually, and with others, on data management, qualitative secondary analysis and the ethical issues associated with big data. Her work has been critical in supporting the sharing and re-use of qualitative data, and advancing a more nuanced understanding of secondary data analysis.
researchers and data producers, with specialisation in ethics of data use: consent, confidentiality, anonymization and secure access to data. She also teaches workshops on secondary analysis of qualitative data. Libby worked as a Senior Research Archivist at the University of Leeds, where she was responsible for creating and managing the Timescapes archives and providing support for those using the data. Libby has published individually, and with others, on data management, qualitative secondary analysis and the ethical issues associated with big data. Her work has been critical in supporting the sharing and re-use of qualitative data, and advancing a more nuanced understanding of secondary data analysis.