
Today’s post is written by Dr Emma Davidson, and her colleagues Justin Chun-ting Ho and Professor Lynn Jamieson in Sociology at the University of Edinburgh. The blog considers the potentials and pitfalls of using R, a tool for computational text analysis, to get an overview of a large volume of qualitative data and to identify areas of salience to explore further. Emma and colleagues draw on a recent ESRC National Centre for Research Methods study – Working across qualitative longitudinal studies: A feasibility study looking at care and intimacy – conducted by Prof Rosalind Edwards, Prof Lynn Jamieson, Dr Susie Weller and Dr Emma Davidson.
Computational text analysis using R in Big Qual data: lessons from a feasibility study looking at care and intimacy
The use of computational text analysis has increased rapidly across the humanities and social sciences. Much of this growth has centred on taking advantage of the breadth of new digital sources of data and the rich qualitative material they provide. Despite this progress, the application of these approaches to qualitative methods in the social sciences remains in its infancy. Our project is one such endeavour. Together with colleagues – Professor Rosalind Edwards, Dr Susie Weller and Professor Lynn Jamieson – it involved secondary analysis of six of the core studies stored in the Timescapes Qualitative Longitudinal Data Archive. Using a substantive focus on practices of care and intimacy over time, and across the life course, we wanted to explore the methodological possibilities of working with large volumes of qualitative data. We also wanted to address the scepticism that ‘scaling up’ could damage the integrity of the qualitative research process.
The breadth-and-depth method
From the outset, our intention was to develop an approach, which integrated computer-assisted methods for analysing the breadth of large volumes of qualitative data, with more conventional methods of qualitative analysis that emphasise depth. This would – we hoped – take us away from the linearity implied by ‘scaling up’, towards an iterative and interpretative approach more akin to the epistemological position of the qualitative researcher. A discussion of our breath-and-depth method is detailed in Davidson et al. (2019). One of our first analytical steps was to ‘pool’ the data into a new assemblage classified by gender and generation-cohort. Too large to read or analyse using conventional qualitative research methods, we looked to computer-assisted methods to support our analysis. What we were seeking was a way of ‘thematically’ mapping the landscape of the data. Rather like an archaeologist undertaking geophysical surveying, we anticipated using this surface survey to detect ‘themes’ for further exploration. Once identified, these themes would be analysed using shallow test pit sampling, the aim of which is to ascertain if they are worthy of deeper investigation. We expected a recursive movement between the thematic mapping and the preliminary analysis. So, where a possible theme proved to be too ambiguous or tangential, it would be eliminated, followed by a return to the thematic mapping to try again. If a theme(s) relevance is confirmed, the move to in-depth interpretive analysis can be made.
Thematic mapping and computer-assisted text analysis
There are, of course, various ways of undertaking computer-assisted approach to thematic mapping. And as part of the project we experimented – more and less successfully – with various text analytics tools, including Leximancer, Wordsmith, AntConc and R. In each, we were broadly interested in text analysis, exploring for instance word frequencies, word proximity and co-location, conducting searching for words within pre-defined thematic clusters (for example, relating to performing practical acts of care and intimacy), as well as keyword analysis.
We wanted to explore R since it provided the ability to write the programming language ourselves and change the form of analysis according to any emergent results. This not only meant that we were in control of the programming steps, but also that these steps were transparent and understood. The limitation – of course – is that we were a team of researchers whose skills were primarily in qualitative data analysis! And while we were capable of undertaking statistical analysis, we had no prior experience of statistical programming languages, nor of natural language processing. It became clear that in order to proceed we didn’t just need a skilled R user to produce the analysis for us, but a collaborator who could go on this journey with us. This proved a difficult task since the majority of those we approached were skilled in computational methods, yet were not familiar or sufficiently interested to collaborate in a project where the focus was on qualitative research methods. This reluctance perhaps reflects the tendency for qualitative methods to use small-scale and intensive approaches which focus on the micro-level of social interactions. Computational scientists, conversely, have focused on big data to understand social phenomena at an aggregate level. By seeking to bring these skills together, our study presented possible collaborators not only with an unfamiliar form of data, but also an unfamiliar approach.
Using R to analyse Big Qual data
We were – eventually – lucky enough to recruit Justin Chun-ting Ho to the project, a doctoral candidate from the University of Edinburgh and in collaboration we developed a plan for the proposed work. A priority was to conduct a comparative keyword analysis to identify ‘keyness’ by gender and generation cohort. We were also keen to ‘seed’ our own concepts by creating pre-defined thematic word clusters, and examining their relative frequency across the different categories of data. How does the frequency of positive emotion words, for example, compare between the youngest and oldest men?
Using keyword analysis, we were able to gain both general insights, as well as potential areas for further exploration. We found, for example, that relationship and emotion words occurred with a greater frequency amongst women, as did words related to everyday or practical acts of care, such as ‘feed’ and ‘dress’. Conversely, we found that words relating to work and leisure activities were most common amongst men. Changes across the life-course were also noted, with family – predictably – becoming more salient feature of life for older generations. As an example, the figure below shows a comparison of the oldest and youngest women, and the shifting focus from friends to family.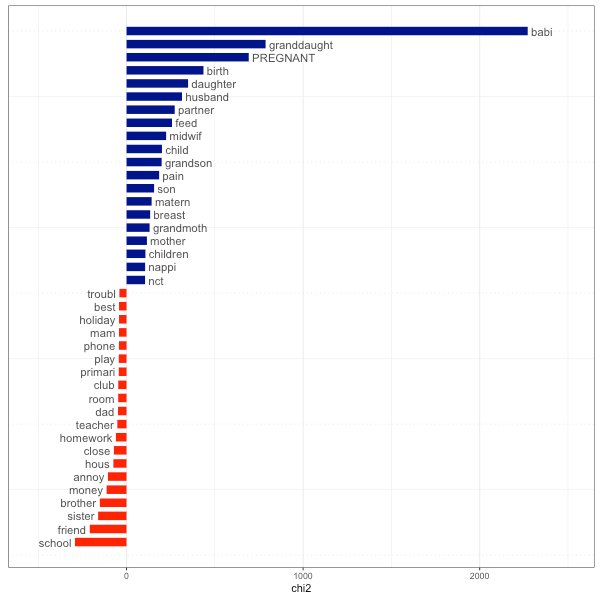
Figure 1: Comparative keyword analysis: pre-1950 (oldest) versus post 1990 (youngest) women
We were also, however, aware that the results reflected the complexity of speech itself (for example, the meaning of ‘care’), while some concepts were structured strongly by individual projects (for example, the frequent use of siblings was, to a large extent, a function of its prevalence in one of the core Timescapes projects, rather than coming from naturally occurring speech). It also raised the question of the extent to which examples of care and intimacy were neglected due to the parameters used to define keyness – that is, we were looking at the keyness of all words, not just those words related to care and intimacy.
These reflections were themselves useful since it provides us an opportunity to critically evaluate the tacit theory underpinning our understandings of what constitutes practices of care and intimacy. Where we benefited from R was in its flexibility, since we were able to explore a range of alternate forms of analysis to integrate further. For example, we went on to manually identify care and intimacy keywords, and to combine them into thematic ‘clusters’ that share some characteristic (for example, conflict words, relationship work, words describing practical acts of care and words describing formal childcare). We then counted the frequency of words from each cluster using R to show the thematic differences between interview transcripts of different genders and generations. In this way, we were able to augment human effort with the power of machine; qualitative analysis allowed us to identify the themes while computational techniques could show the prevalence of such themes within the corpus, which would otherwise be too big for qualitative analysis. This thematic analysis, in turn, provided further outputs, which identified specific themes (including ‘love’ and ‘arguments’ for exploration through shallow test pit analysis, see Davidson et al. 2019).
Reflections and moving forward
The project, overall, has shown that text analytics can provide a unique opportunity for qualitative researchers seeking to interrogate large volumes of qualitative data. We concur with Gregor Wiedemann’s contribution in this collection that these methods can extend and complement the qualitative researchers’ toolkit. Our work with R has provided tangible benefits, and crucially supports the breadth-and-depth approach developed by the project. However, unlike pre-programmed and commercially available software such as Leximancer, R requires a certain level of competency in statistical programming language – and crucially the time and resources to invest in developing these skills. It is perhaps for this reason that our analysis ultimately relied on Leximancer, and its accessible, user-friendly interface.
Qualitative researchers are not unique – many social scientists, regardless of methodological orientation, do not have these skills. Yet given the rise of big data and possibilities it offers the social sciences, the value of text analytics is likely to grow – as will demand for its application. To bridge this chasm, investment is needed in training, capacity building and multi-disciplinary working. The method developed through our project provides one such way of building this interdisciplinary bridge. However, it also revealed the importance of developing text analytic skills directly into bids for funding – either through a named collaborator equally invested in the project outcomes, or sufficient resources for the training and development of the team. Looking forward, we anticipate with excitement the collaborative opportunities that the ‘big data’ era presents to qualitative researchers.
References
Davidson, E., Edwards, R., Jamieson, L. and Weller, S. (2019) Big data, Qualitative style: a breadth-and-depth method for working with large amounts of secondary qualitative data. Quality and Quantity. 53(363): 363-376.