
 Dr Gregor Wiedemann works in the Natural Language Processing Group at Leipzig University. He studied Political Science and Computer Science in Leipzig and Miami. In his research, he develops methods and workflows of text mining for applications in social sciences. In September 2016, he published the book “Text Mining for Qualitative Data Analysis in the Social Sciences: A Study on Democratic Discourse in Germany” (Springer VS, ISBN 978-3-658-15309-0).
Dr Gregor Wiedemann works in the Natural Language Processing Group at Leipzig University. He studied Political Science and Computer Science in Leipzig and Miami. In his research, he develops methods and workflows of text mining for applications in social sciences. In September 2016, he published the book “Text Mining for Qualitative Data Analysis in the Social Sciences: A Study on Democratic Discourse in Germany” (Springer VS, ISBN 978-3-658-15309-0).
In this blog, he discusses computational textual analysis and the opportunities it presents for qualitative research and researchers.
Computer-assisted text analysis beyond words
In our digital era, amounts of textual data are growing rapidly. Unlike traditional data acquisition in qualitative analysis, such as conducting interviews, texts from (online) news articles, user commentaries or social network posts are usually not generated directly for the purpose of research. This huge pool of new data provides interesting material for analysis, but it also poses qualitative research with the challenge to open up to new methods. Some of these were introduced in blog post #4. Here, computer-assisted text analysis using Wordsmith and Wordstat were discussed as a means of allowing an ‘aerial view’ on the data, e.g. by comparative keyword analysis.
Despite the long history of computer-assisted text analysis, it has stayed a parallel development with only little interaction with qualitative analysis . Methods of lexicometric analysis such as extraction of key words, collocations or frequency analysis usually operate on the level of single words. Unfortunately, as Benjamin Schmidt phrased it, “words are frustrating entities to study. Although higher order entities like concepts are all ultimately constituted through words, no word or group can easily stand in for any of them” (2012). Since qualitative studies are interested in the production of meaning, of what is said and how, there certainly are overlaps with lexicometric measures, but nonetheless their research subjects appear somewhat incompatible. Observation of words alone without respect to their local context appears as rough simplification compared to a hermeneutic close reading and interpretation of a text passage.
The field of natural language processing (NLP) from the discipline of computer science provides a huge variety of (semi-) automatic approaches for large scale text analysis, and has only slowly been discovered by social scientists and other qualitative researchers. Many of these text mining methods operate on semantics beyond the level of isolated words, and are therefore much more compatible with established methods of qualitative text analysis. Topic models, for instance, allow for automatic extraction of word and document clusters in large document collections (Blei 2012). Since topics represent measures of latent semantic meaning, they can be interpreted qualitatively and utilised for quantitative thematic analysis of document collections at the same time. Text classification as a method of supervised machine learning provides techniques even closer to established manual analysis approaches. It allows for automatic coding of documents, or parts of documents such as paragraphs, sentences or phrases on the basis of manually labelled training sets. The classifier learns features from hand coded text, where coding is realised analogously to conventional content analysis. The classifier model can be seen as a ‘naïve coder’ who has learned characteristics of language expressions representative for a specific interpretation of meaning of a text passage. This ‘naïve coder’ then is able to process and code thousands of new texts, which explicitly opens the qualitative analysis of categories up to quantification.
In my dissertation study on the discourse of democratic demarcation in Germany (Wiedemann 2016), I utilised methods of text mining in an integrated, systematic analysis on more than 600,000 newspaper documents covering a time period of more than six decades. Among others, I tracked categories of left-wing and right-wing demarcation in the public discourse over time. Categories were operationalised as sentences expressing demarcation against, or a demand for, exclusion of left-/right-wing political actors or ideologies from the legitimate political spectrum (e.g. “The fascist National Democratic Party needs to be banned” or “The communist protests in Berlin pose a serious threat to our democracy”). Using automatic text classification, I was able to measure the distribution of such qualitatively defined categories in different newspapers between 1950 and 2011. As an example, the following figure shows relative frequencies of documents containing demarcation statements in the German newspaper, the Frankfurter Allgemeine Zeitung (FAZ).
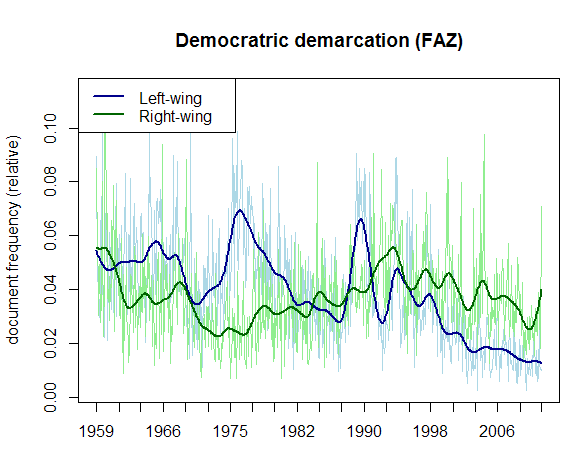 Distribution indicates that demarcation towards left-wing actors and ideology long-time superseded right-wing demarcation. Soon after 1990, the latter became the primary discourse subject of threats of German democracy. The enormous benefit of automatic classification is that it allows for easy comparison of publications (e.g. other newspapers) or relations with any other category. For instance, the distribution of “reassurance of democratic identity”, a third category I measured, strongly correlates with right-wing demarcation, but not with left-wing demarcation. Such a finding can be realised only by a combination of the qualitative and the quantitative paradigm.
Distribution indicates that demarcation towards left-wing actors and ideology long-time superseded right-wing demarcation. Soon after 1990, the latter became the primary discourse subject of threats of German democracy. The enormous benefit of automatic classification is that it allows for easy comparison of publications (e.g. other newspapers) or relations with any other category. For instance, the distribution of “reassurance of democratic identity”, a third category I measured, strongly correlates with right-wing demarcation, but not with left-wing demarcation. Such a finding can be realised only by a combination of the qualitative and the quantitative paradigm.
While computer-assisted methods support qualitative researchers clearly in their task of retrieving “what” is being said in large data sets, they certainly have limitations on the more interpretive task of reconstructing “how” something is said, i.e. the characterisation of how meaning is produced. It is an exciting future task of qualitative research to determine how nowadays state-of-the-art NLP methods may contribute to this requirement. In this respect, computational analysis extends the toolbox for qualitative researchers by complementing their well-established methods. They offer conventional approaches new chances for reproducible research designs and opportunities to open up to “big data” (Wiedemann 2013). Currently, actors in the emerging field of “data science” are a major driving force in computational textual analysis for social science related questions. Since I repeatedly observe lack of basic methodological and theoretical knowledge with respect to qualitative research in this field, I look forward to a closer interdisciplinary integration of them both.
Further reading
Blei, David M. 2012. “Probabilistic topic models: Surveying a suite of algorithms that offer a solution to managing large document archives.” Communications of the ACM 55 (4): 77–84.
Schmidt, Benjamin M. 2012. “Words alone: dismantling topic models in the humanities.” Journal of Digital Humanities 2 (1). Url http://journalofdigitalhumanities.org/2-1/words-alone-by-benjamin-m-schmidt.
Wiedemann, Gregor. 2013. “Opening up to Big Data. Computer-Assisted Analysis of Textual Data in Social Sciences.” Historical Social Research 38 (4): 332-357.
Wiedemann, Gregor. 2016. Text Mining for Qualitative Data Analysis in the Social Sciences: A Study on Democratic Discourse in Germany. Wiesbaden: Springer VS, Url: http://link.springer.com/book/10.1007%2F978-3-658-07224-7.
2 pings